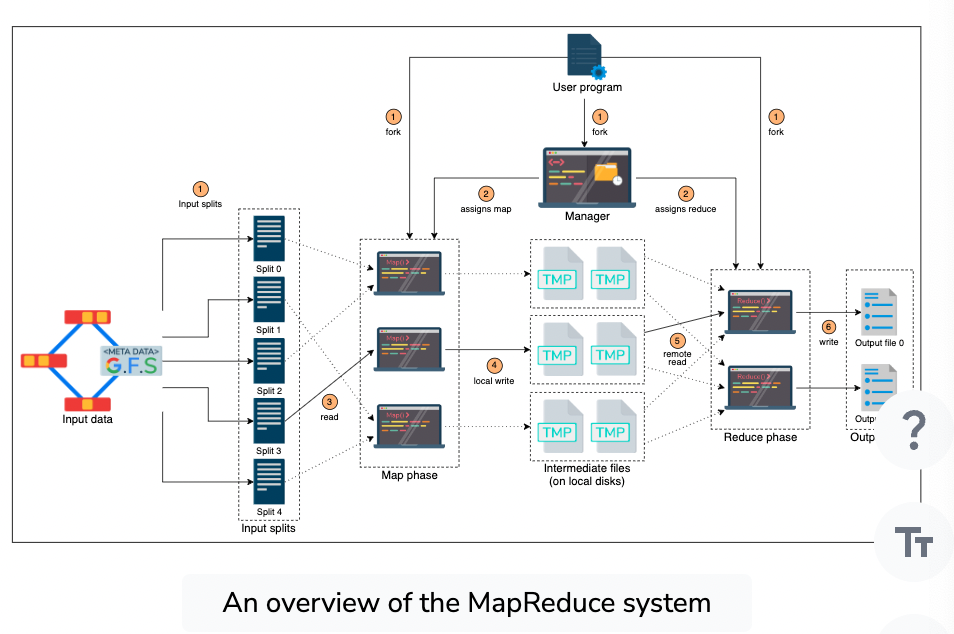
Divide the input data into a specific number of splits
Then process those individually on workers using a Map function
Clients only provide the map and the reduce
If values are too large, we feed to the Reduce function via an iterator
The manager holds all the state, controlling the subordinate tasks and acts as a relay for intra-worker communications. Stores the identity of each worker and state.
Mapper is a worker that operates on input data splits to produce intermediate results
Reducer - process intermediate kv pairs to produce the output file
Sometimes, if map produces a huge amount of data that’s sharded improperly, a huge amount of keys will go to only a specific reducers
Therefore do a pre-scan of the input data, sampling from it, getting a baseline distribution
Also use a reduce worker to sort the intermediate data
Keep the intermediate filers on the mappers, who then turn into reducers to maintain data locality
How do we deal with stragglers?
If it’s a faulty disk or a machine overload, the manager is responsbile for rescheduling
Design Refinements
Processing
How do to files? Keep track of the key as the offset in the input file, and the value is the content of that file
How do we partition? Normally we just hash the key mod R (where R is the reducers), but we can do a little better
One way: preprocess the key, specific keys can have elements extracted from them for usage. For example, we can do hash(hostname(google.com/blah)) to extract google.com out
Combiner functions
We can use a combiner function (basically a sort | uniq) to preprocess values before they go to the reducer for reduced network bandwidth usage
Key thing is that both the map and reduce functions expect functions that are deterministic and idempontent so that they can retry if needed
Misc
Status pages, workers need to report their state and users need to be able to see the state on master
Each worker holds a local counter object and periodically sends the success, failed, etc count to the manager
Skipping bad records
Sometimes records are bad, and we need to skip it
Whenever a worker dies from processing a request, it sends an error message to the manager, who then keeps tracks of errors on that particular key or offset. If the sequence number is high enough, it marks the job as skipped
Profiling tools should also be provided to help guide swes
Managers need to have a shadow, and one that starts back up
Streaming data?
We can accomplish this by collecting mini batches as the straem comes in