fasttext
Bojanowski, Piotr, Edouard Grave, Armand Joulin, and Tomas Mikolov. “Enriching Word Vectors with Subword Information.” arXiv, June 19, 2017. https://doi.org/10.48550/arXiv.1607.04606.
- Based off of ngrams
- uses numerically stable transformations, logs to avoid underflow
- very simple, 1 layer neural network basically
Joulin, Armand, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov. “FastText.Zip: Compressing Text Classification Models.” arXiv, December 12, 2016. https://doi.org/10.48550/arXiv.1612.03651.
-
Very simple as well, vector compression by using a codebook: product quantization
-
notes that “the norms of the vectors are widely spread, typically with a ratio of 1000 between the max and the min”
-
turns out you can prune the most common words (those with lowest entropy)
- you can also prune out the vectors that don’t add very much (i.e. low norms)
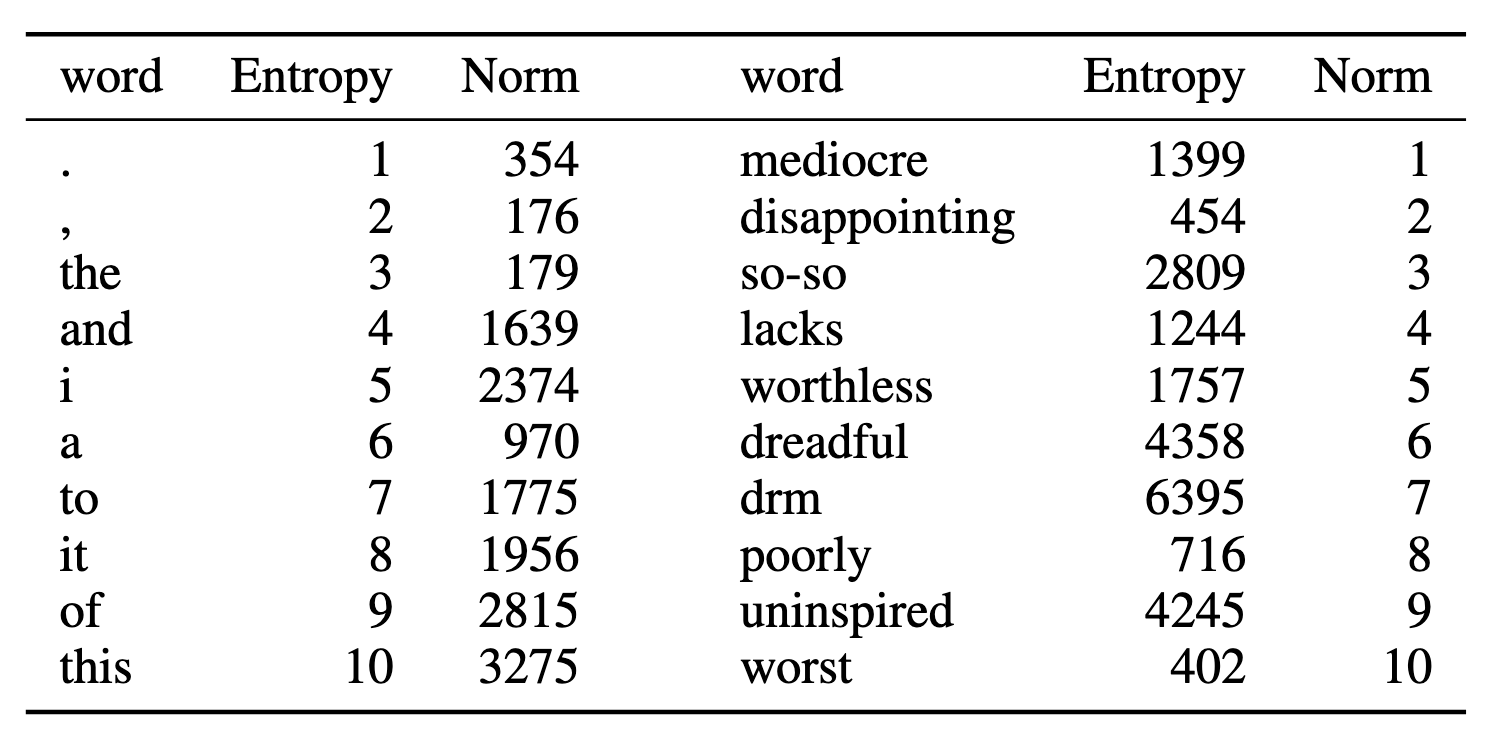
- the prunables: periods and commas don’t add anything so low entropy, mediocre/disappointing/so-so etc don’t add much value, so low norm