k/v stores
Tags: Databases
RocksDB
- Dong, Siying, Andrew Kryczka, Yanqin Jin, and Michael Stumm. “RocksDB: Evolution of Development Priorities in a Key-Value Store Serving Large-Scale Applications.” ACM Transactions on Storage 17, no. 4 (2021): 1–32. https://doi.org/10.1145/3483840.
MyRocks
- https://www.youtube.com/watch?v=Lxbb_7q8iRo
- Better SSD efficiency
- Better space efficiency
- “if you fit the entire working set in ram, you have too much ram?”
- If all working set is in RAM, then you’re not being efficient with your ram
- What if we are writing back pages with one bit change? Terrible write amplification, only rows in LSM trees
- Are you trying to read keys that don’t exist? B-trees have this issue
- LSM tree is more space efficient than b-trees
- wasting 1/3rd to 1/2 of the pool, but 10% with LSM tree. How?
- Better write efficiency is that you use less space so less write efficiency
- Secondary indices?
- RocksDB is very hard to tune
rocksdb_block_cache_sizerocksdb_max_background_compactions
- Uncommitted changes are buffered in memory by myrocks for tx’s
- Performance

SpeedDB - https://github.com/speedb-io/speedb
ZippyDB
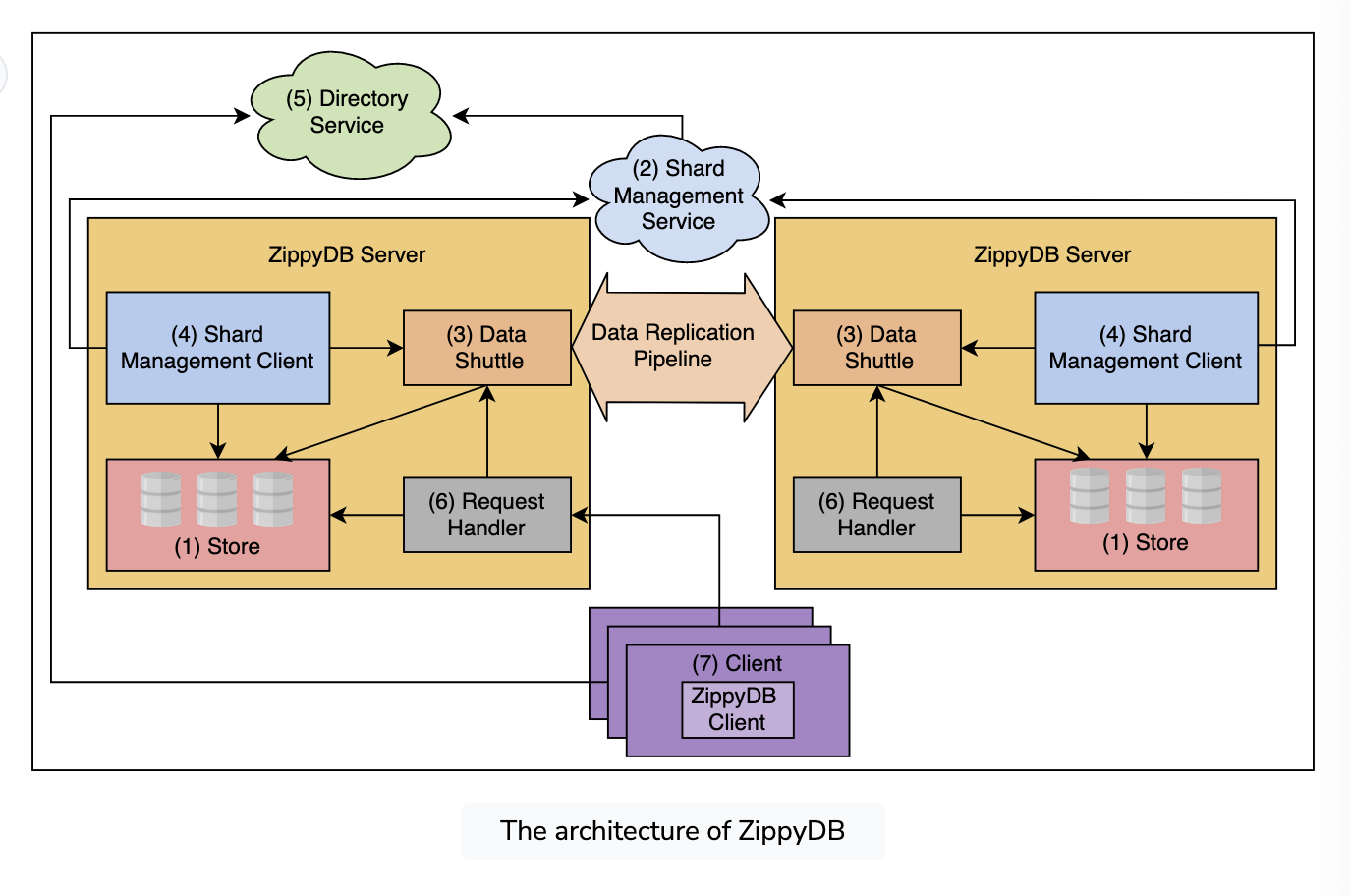
- Build on RocksDB, but less management
- Generic KV store, supports snapshot reads and partial read/write
- Snapshot reads
- cheap operation that uses snapshot handlers to perform multiple reads
- basically RCU, but if you read while a write is happening the read goes to a snapshot
- handles versions, whereas RCU doesn’t handle versions
- also uses a cleaner or garbage collector or sweeper, whereas RCU places the burden on the writer
- Data can be replicated either with gossip protocols or paxos, although usually there’s a master
- specific read only replicas called followers are occasionally added for high volume reads
- Divides times into small epocs, each epoc zippy assigns a primary replica, that is the paxos leader
- Allows clients to choose which consistency level they come into (same as Spanner)
- Consistent reading -> clients go to the current primary of the shard
- Stale information -> can go to a replica
- Also allows for read-your-writes with a hash that signals to the replicas to manually update
- Has a data shuttle, which basically tiers it into Primary -> Secondary -> Follower, on per shard basis
- A shard is a box
- Shard management service is the orchestrator, and tells each shard what they own, master that runs over the control plane
- Store is based on top of RocksDB
SILT Design -> From Cassandra/dynamo
- Scalable Index Large Table, that internally uses multiple stores
- \(read amplification = {data read from storage}/{data read by application}\)
- \(write amplification = {data written to storage}/{data written by application}\)
Note which things we can put in RAM vs Storage
- RAM: index and filter, filters, index
PUTandDELETEare both managed here
- Storage: log, hash tables, sorted things
Looking up logs via In Memory Hash Table
- Write friendly store will append all
PUTandDELETEinto an in-storage log which makes the writing process fast, incoming requests are recorded as a write ahead log - Keep an in memory hash table that maps keys to their offset in the log, each entry in the hash table is added right after a successful entry in the in-storage log
- Use a partial-key cuckoo hashing
- Use part of the key, cuckoo hashing requires two ahsh functions, each of which map to two candidate buckets in the hash table.
- Inserting/deleting a key:
- compute buckets
h1(K1)andh2(K1), and check if one or both or none of the two buckets are empty - If at least one bucket is empty, insert it into the bucket
- If both buckets are occupied, move or create a new table
- compute buckets
- Doing a get:
- if we do a get, look it up in the hash table. If there’s nothing in the hash table, go to the intermediary stores
Intemediary Stores
-
When the write-friendly store is full, it needs to create a new instance for further insertions
-
Basically compacts the log into a smaller log, sorted by hash
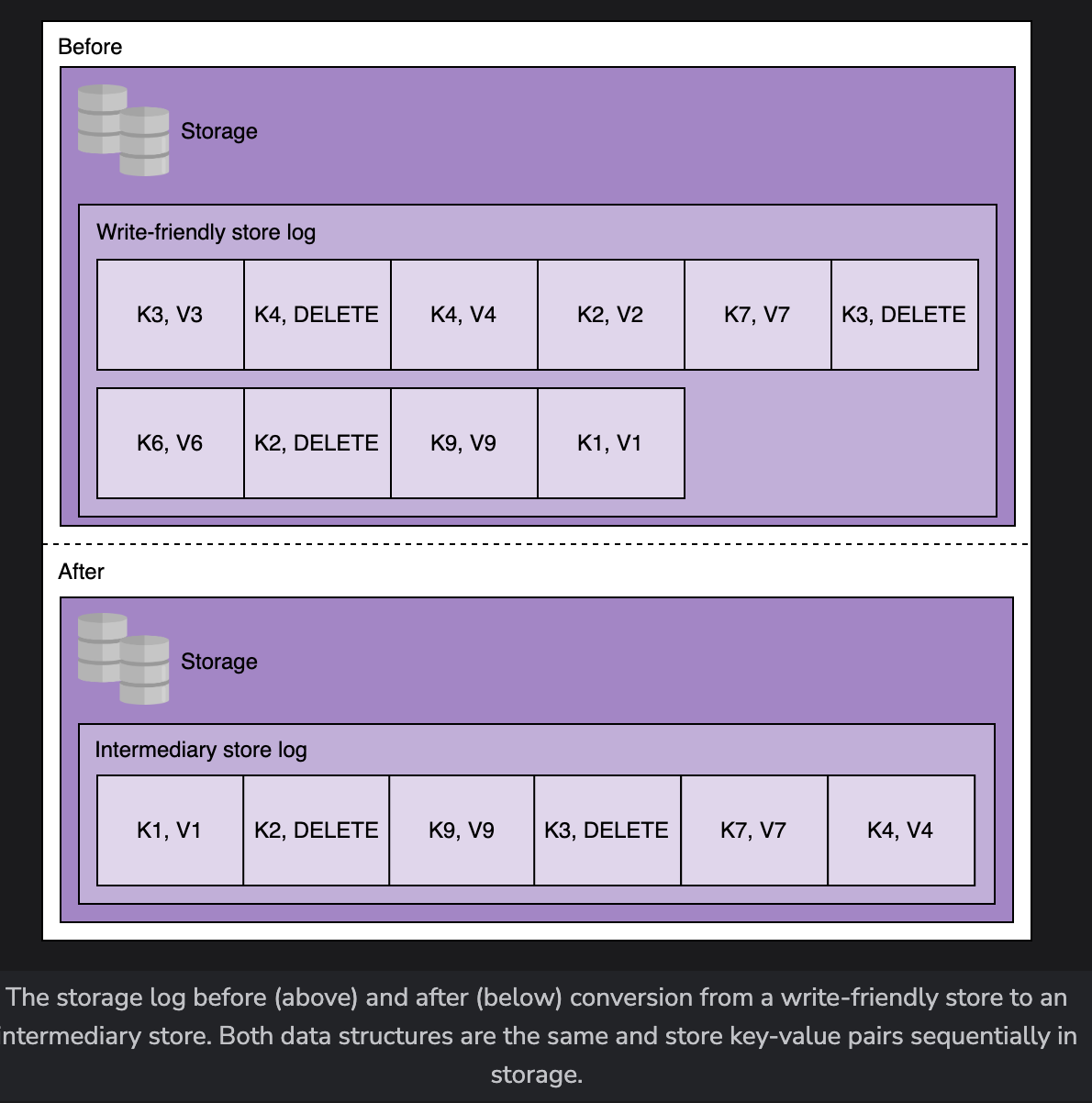
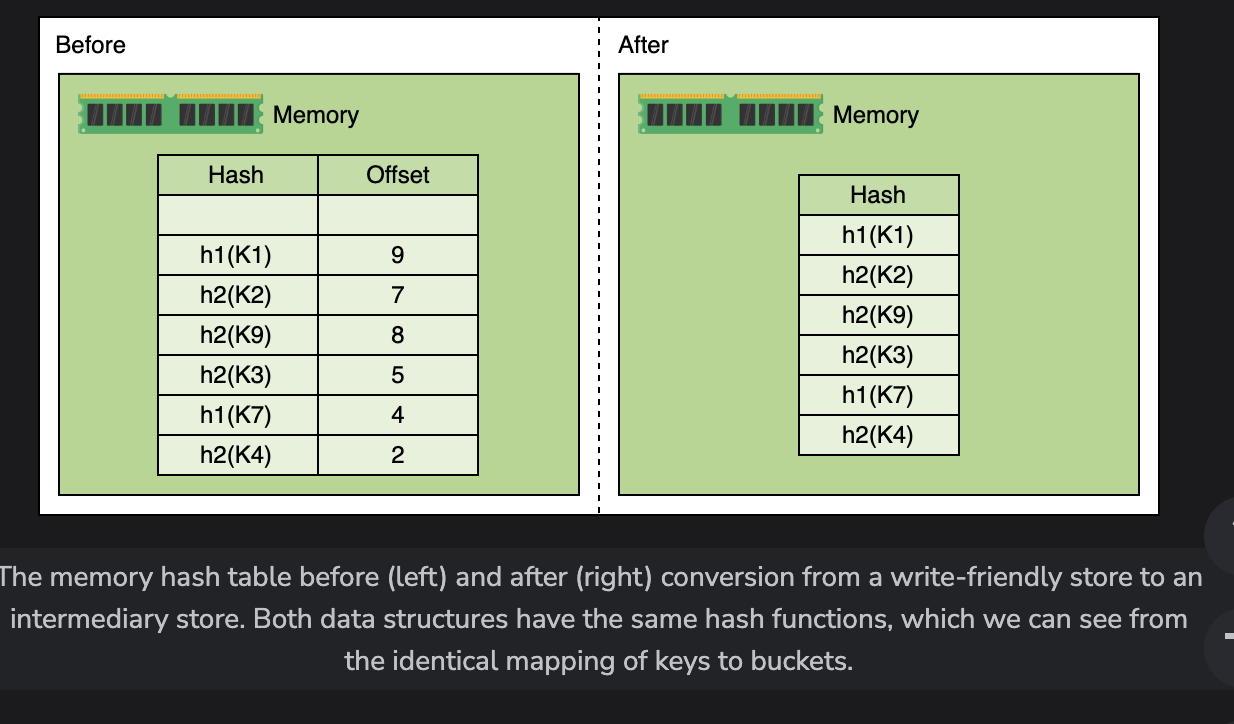
- Similar to before, GETS can just use the hash table except it’s compacted for retrivals
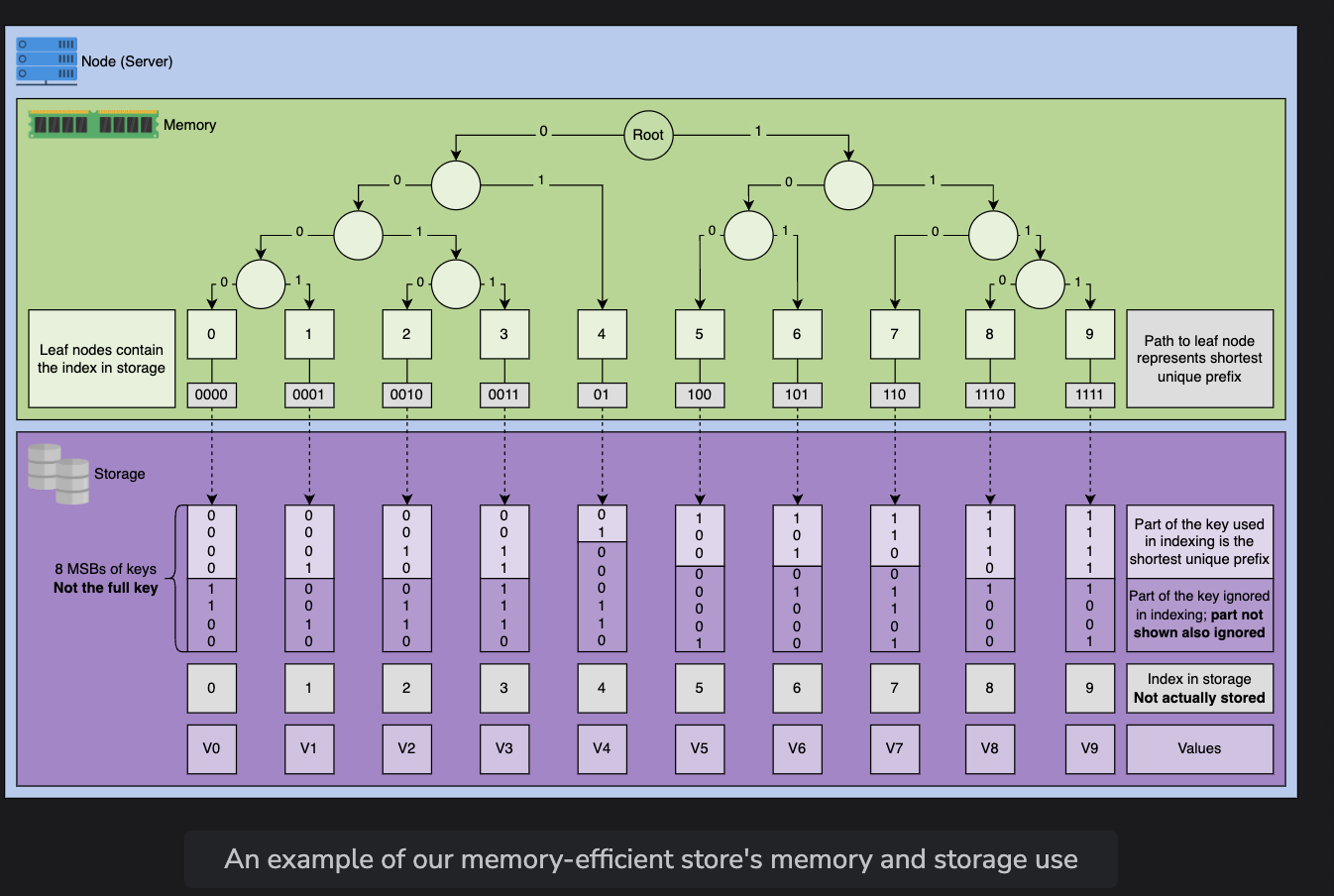
Memory Efficient Store
-
At the final level, we need to compact more. These will sort keys and merge them using a trie