paxos
algorithms, distributed systems
- FLP impossiblity result means that even if one crash is tolerated in an async system, consensus cannot be reached
Tradeoffs Table
| Algorithm | Leader Election RTTs | Voting RTTs (General Case) | Voting RTTs (Optimistic Case |
|---|---|---|---|
| Fast Paxos | n/a (leaderless) | 2 | 1 |
| multi-paxos | 1 | 2 | n/a |
| epaxos | n/a (leaderless) | 2 | n/a |
| raft | 1 | 2 | n/a |
Implementation of Paxos
- Paxos is generally used to keep track of a log, and decide which values are appropriate to commit to a log
- Divded into proposers, acceptors, and learners
- Proposers send their proposals to other replica group members, and tries to have a majority of members support their proposal.
- Acceptors are the group members who receive proposals or reject them
- Learners keep track of accepted values, and mark them as chosen. Learners are basically voters that help consensus
Steps
- Two steps, first a majority voting step and and commit steps.
- The reason there’s two steps is because of the potential for a split vote, where the acceptor only accepts the first value, and no majority is chosen
- Conflicting choices can also happen and result in ABA
- However, two phases is not enough to enforce safety, we must have additional members
- Proposal numbers play a vital role, acting as logical clocks.
Actual steps:
- Handshake phase - prepare-promise message, a prepare request is sent by each proposer to all acceptors.
prepare(proposal_number)is called, everyone either accepts or rejects the proposal- If the acceptor hasn’t yet promised to any other prepare request, it records the proposal number and sends a promise to the proposer
- If the acceptor also already promised to a pepare request with lower proposal number, it makes a promise with the newer one and breaks the promise with the already promised request.
- If the acceptor has already promised to a prepare request with the higher numbered proposal, it simply requests the current one
- If the acceptor has already accepted an accept request with a lower proposal number, it makes a promise to the current rprepare, and sends back the accepted proposal number and the corresponding value
- Value acceptance phase - accept-accepted messages
- If the proposer receieves a promise from the majority of acceptors, it sends an accept request
accept(proposal_number, value) - This includes the value so that
- If the proposer didn’t recieve any accepted proposals along with the promise message in response to the prepare requests, then it will propose a value of its choice
- If the proposer received already accepted proposals by the acceptors, along with the promise messages in response to the prepare requests, then it has to select the value with the highest proposal number
- An acceptor, on recieving an accept request, responds to the proposer
- If the latest proposal number promised by the acceptor is the same as in the accept request, it will accept the request and respond to the proposer with an accepted message. If the proposer recieves majority acceptance of the proposed value, the value is chosen and broadcast to everyone
- If the acceptor has promised to a new proposal with the higher proposal number, it rejects the accept request, and the protol has to start again
- If the proposer receieves a promise from the majority of acceptors, it sends an accept request
Liveness Issues
- Since an acceptor always promises on a proposal, it can lead to a situatiion where accept rejects sent by a proposer are always being rejected by the acceptors if there is lag.
- If every time the acceptors recieve a prepare request with a higher proposal number before receiving an accept requests against a proposal that the acceptors promised earlier, none of the accept requests will be accepted.
- To solve this, only single proposers are allowed to issue proposals (aka leaders)
Other Considerations
- Why majority instead of highest number? Could result in ties
- Why two steps? Having a majority always choose a value is bad because then you could get overmatching writes
Multipaxos
- Basically between paxos rounds, if you have the same leader, you can just just propose and commit, since you know there’s no competing proposer
Boxwood
- Old system used to explore the feasibility of various stages in DB locks
Chubby
- Google locking system that predates Zookeeper
- Used by GFS (Google File System) to appoint a manager server and stores small amounts of data
- Used by BigTable to elect bigtable amanger, discover servers, enable clients to locate Bigtable manager, and low volume storage
Requirements
- Provides 3 APIs: whole file reads and writes, advisory locks, and notification of events
- Coarse grained locking service, you can lock with minimal overhead, and is a reliable low volume storage
- Also needs to be available and reliable, and have decent throughput
Design
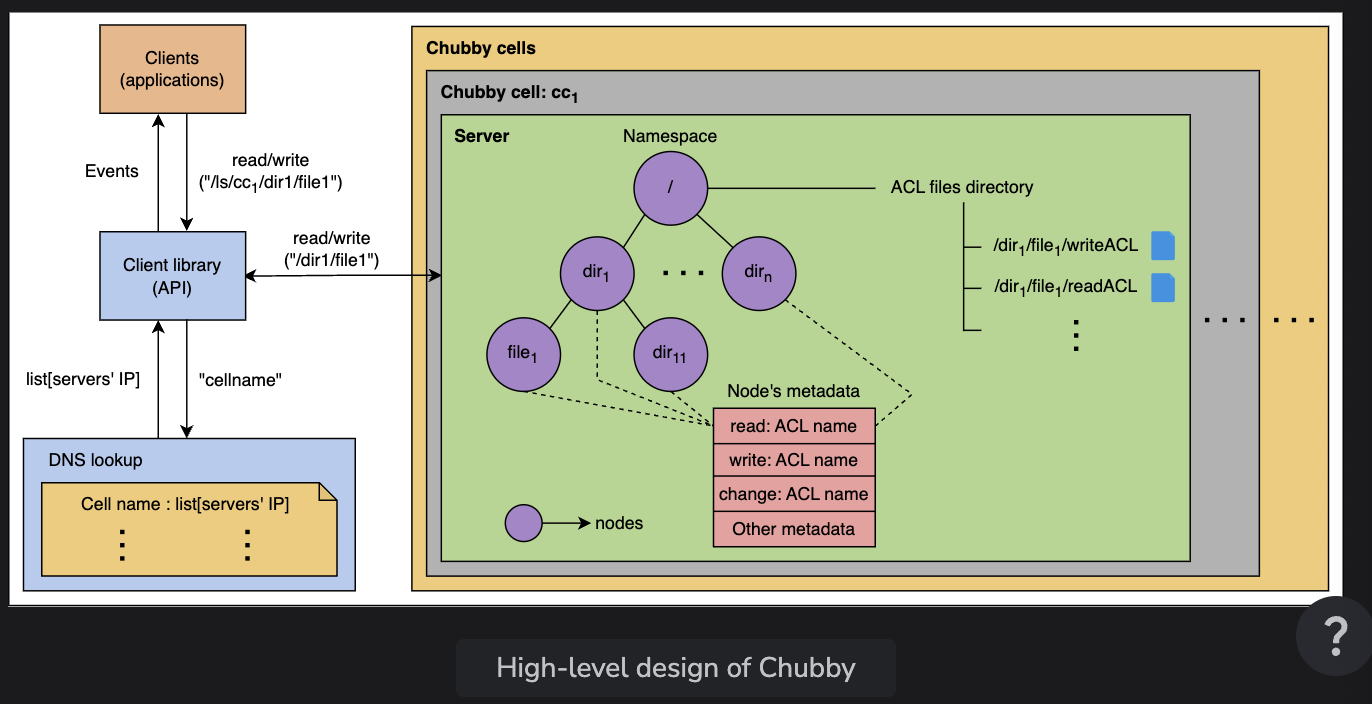
Chubby Cell
- Chubby cell is multiple serbers (usually 5), which replicate with each other
- Each server has a namespace composed of directions and files, with ACLs
- One replica is always elected as the primary, which initiates read and write operations
- Replicas copy the database using a consensus protocol and elect new primaries as needed
- Clients discover the primary by asking any server within the cell which is the primary, and caches it on the client side. It uses this as the primary until the server stops being the primary
- Two types of requests
- Writes: propagated to all the replica servers, are async and only acked when a quorum responds
- Reads: serviced by the primary replica
- Each file or directory within a chubby server is knownas a
node(similar to a inodes)- Each node has a unique name, there’s emphemeral and permanent nodes
- Ephemeral nodes are similar to temp files, they get deleted when no client has them open
- Uses ACLs in the directory that keeps track of authorized names
Chubby Library
- Each client communicates with chubby cells via the client
- Keeps track of the primary replicas to communicate with
Locking
- multiple clients can hold a lock in reader mode, only a single client can hold a writer lock
- Locks are adivsory, which means you don’t need a lock to read a file. Clients are required to cooperate for conflicts, but advisory locks are more scalable rather than mandatory locks, and clients can emulate strict locking easily (just have them explicitly check for locks)
- If clients are holding a read lock, a write lock cannot be acquired
Sequencers and lock delays
- If you hold a lock and never release it, then we have issues
- Sequence numbers are introduced after a lock is acquired
- Locks that are not released are expired, and we use sequence numbers to note the current state (similar to a lamport clock)
- If a lock becomes free after an expiration, the lock server does not let any other client claim it for a specific time period. This is used to create a backoff from faulty clients claiming a lock, then releasing, then claiming it again.
- To allow systems to know what is happening, Chubby sends events: modifying file contents, modifying nodes, replica failover, handles, locks, conflicts, etc
Caching
- Primaries keeps a list of data that clients are caching and sends invalidations to the clients to keep them consistent
- If data or metadata needs to be changed, the primary blocks modifications and sends invalidations to clients with the relevant data cached
- When a client receives an invalidation, it flushes the invalid state and acks it with a keepalive
- If there’s no acks for invalidations, then the primary keeps the node uncachable
Sessions
- A client and a cell keep track of each other with sessions that are held with keepalives
- A session comes with a lease, which is defined as a time period where the primary will tell the client with updates and will not terminate the connection unilaterally
- The lease is used by the local client to know if something has gone wrong, if it’s missing keepalives
- If a local lease times out, then the client
- Empties and disables the cache
- Waits for a grace period, and tries keepalives
- If it connects it, then enable the cache
- If nothing, then assume terminated
- If a local lease times out, then the client
Failovers
- If a node cannot communicate with the primary after the lease ends, it starts and election
- Periodically, the primaries keep a keepalive for the leadership
- Each cell’s primary takes snapshots and backs it up
- Mirroring can also occur across different regions, and a mirror that cannot be accessed remains unaltered until communication is reestablished. Updated files are located by contrasting their checksums
- Failure steps for replicas that do not recover after a few hours
- A replacement system is used to provision a new replica
- It initaties the lock server binary
- DNS tables are updated
- Current primary replica also has to have this info, which it polls for
- Cell DB is updated
- Replica servers update themselves with the new member
- New server recieves information
- Afterwards, it is permitted to vote in an election after it processes a write
Proxies and Partitioning
- Proxies act as LB’s by allowing KeepAlives to be decreased to the main server
- Partitioning allows us to shard chubby’s namespace, where different namespaces set different replicas
Design Decisions
- Use a lock service for centrally managed things
- Permit a huge number of clients to access a Chubby file without using many servers
- Use event notification instead of polling because clients and replicas may want to know when things have changed
- Cache the data on the client side
- Use consistent caching because developers get confused by non-intuitive caching semantics
- Redirecting all reads and writes via a single node was the way to provide strong consistentcy. Caches and proxies make up for the loss in R/W throughput
Differences from Boxwood
- Chubby’s aspects (lock system, small file storage, and session/lease management) are one thing, whereas boxwood had three different peices
- Chubby has a more advanced interface than boxwood
- Boxwood had a 200ms lease period, whereas Chubby’s is 12
- Chubby has a grace period to prevent losing locks
Coarse grained vs fine-grained locking
- Coarse grained locks will need much less load on the lock server, they are rarely acquired
- However, transferring locks from one client to another needs expensive recovery procedures
- Fine grained locks are frequently accessed, which means availability would become critical
- Time penalty for dropping locks would not be severe, since locks are only held for a short period
Zookeeper
API
create(path, data[], mode, flag)- Creates a znode, like an inode, but a unit of abstraction to lock on it
setData(path, data[], version)- sets the data[] in the znode at the specified flag
getData(path, watch)- returns
data[], also allows clients to watch
- returns
getChildren(path, watch)- Returns all the children names of the znode at the specified path
exists(path, watch)- Checks whether a znode exists
delete(path, version)- Deletes a znode. Must match the monotonically increasing versions
Server
- Fully replicated, like etcd, into a set called a
ZooKeeper ensemble - Elected leaders and others become followers
- Unlike chubby, clients can connect to any
- Higher availablity, not as strong consistency
- Use
sync()to assure that you have the highest consistency
- Leader broadcasts operations to the followers, and performs write operation on the coordination data placed in its memory
- Follower can also recieve and respond to write requests. Multiple writes can be batched, but only the request needs to forwarded to the leader, the leader broadcasts all the requests to other followers
- Basically a follower gets a write, sends a request to the leader, the leader broadcasts the state to everyone after it’s done
Replicated Database
- In memory copy of the database so that reads and writes can be done locally
- ZK takes periodic snapshots of all the delivered messages as a WAL
- Snapshots are fuzzy
- Enables at-most-once execution
- If a server dies before the next snapshot is taken, it does a depth first scan of the tree to read every znode’s metadata and data atomically then write that metadata and data from disk, extracted from the WAL
- This is why ZK recovery is slow
Atomic Broadcast
- Used by ZK to broadcast the write request to the replicated database on all servers
- Followers forward writes to leaders
- Uses the ZAB protocol
- Two modes
- Broadcast is used to send messages
- Recovery is used to syncronize
- Default is \(2f + 1\) for quorum where f is the number of faults
- Two modes
- When a leader dies, the new leader is elected and ensures all the updates from the previous leader are incorporated into its replicated db before it broadcasts its own requests
- At every transaction, the leader is broadcasting what it is working on into a replicated queue
Request Processor
- Manager that keeps the transactions atomic, only the leader uses this
- Transactions within ZK are idempotent
- All requests are linearized on the leader, so the leader converts everything into a
setDataTXN
Client-server interactino
getData()andgetChildren()can both be performed locally without notifying others- Servers generate
zxidfor every read request and retrieves the most recently updated state of the server’s data - Writes have multistep
- Write the data
- Notify the client(s) who have set watches on that data
- Sent the write request to the leader so it can be updated in the replicated database
- Data is replicated among all connected servers in the ensemble
- Everything is FIFO, including read requests when there’s a write
- However if a read is in progress, multiple readers can read in parallel
- Like a giant R/W lock
- Default is async transmission of data, which comes at the cost of insconsistent or stale reads
- the
zxidallows the client to maintain a consistent view across different servers - Session timeouts and heartbeats are used to maintain connections from servers to clients for watches, which is decided by the leader
Primitives
-
Config management and service discovery
newZnode = create("/config/port", 8090, EMPHEMERAL) # set a port getData("/config/port", true) # get a watch setData("/config/port", value, version) # new version -
Rendezvous
newZnode = create("/rendezvous/candidateOne", "", EMPHEMERAL) # create a znode to write getData("/rendezvous/candidateOne", true) # get a watch setData("/rendevous/candidateOne", {"10.0.0.1", 8080}) -
Group Membership
newZnode = create("/groups/member0001", EMPHEMERAL) newZnode = create("/groups/member0001/processOne", EMPHERAL,SEQUENTIAL) # set a sequential flag to generate a unique name childrenList = getChildren(/groups/member0001", true) -
Locks
newLock = create("/locks/lock-1", EMPHEMERAL) exists("/locks", true) # watch the lock tree delete(newLock) # to release the lock- issues
-
herding: when a lock is released, many clients stampede to get the lock
- Solved with using
SEQUENTIAL, at which point the lowest sequence number will hold the locknewZnode = create(path + "/lock-", EPHEMERAL, SEQUENTIAL) do childrenList = getChildren(path, false) if newZnode is lowest znode in children exit newPath = znode in childrenList ordered just before newZnode if exists(newPath, true) wait for event while true
- Solved with using
-
exclusive lock only
- Can implement R/W locks with
newZnode = create(path + "/write-", EPHEMERAL, SEQUENTIAL) do childrenList = getChildren(path, false) if newZnode is lowest znode in children exit newPath = znode in childrenList ordered just before newZnode if exists(newPath, true) wait for event while true - create a read lock and then reads can happen with other reads, but blocks on writes, and writes block on reads
- Can implement R/W locks with
-
- Barriers
newZnode = create(path + "/" + processName) exists(path + "/ready", true) newZnodeChild = create(newZnode, EPHEMERAL) childrenList = getChildren(path, false) if fewer children in childrenList than barrierThreshold wait for watch event else create(path + "/ready", REGULAR)
- issues
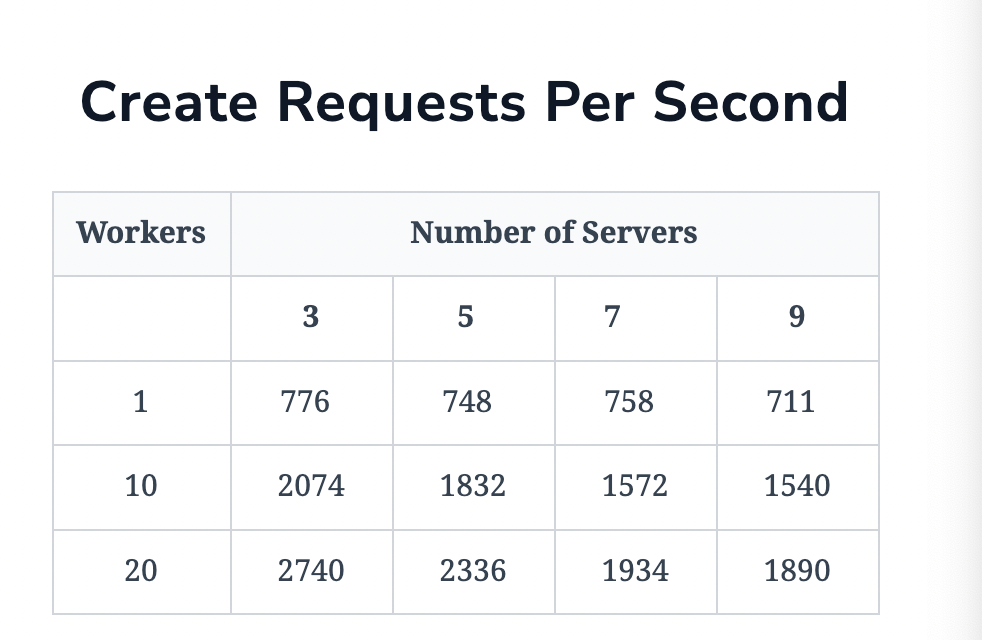
Performance
-
Better load distribution than chubby
-
Atomic broadcast decreases performance, has a CPU cost
-
Failures of leaders will grind application to zero while it recovers
-
Solves chubby like problems with different tradeoffs, gives up consistency for a bit of throughput