swe tea
- Weekly paper club/book club/video club
- Need to figure out timings (tuesday nights?)
- model off of ebpf reading groups and the distirbuted systems reading groups
Profiling a Warehouse Scale Computer
-
Kanev, Svilen, Juan Pablo Darago, Kim Hazelwood, Parthasarathy Ranganathan, Tipp Moseley, Gu-Yeon Wei, and David Brooks. “Profiling a Warehouse-Scale Computer.” In Proceedings of the 42nd Annual International Symposium on Computer Architecture, 158–69. Portland Oregon: ACM, 2015. https://doi.org/10.1145/2749469.2750392.
-
They only used C++, since it made it simpler
-
only on Ivy Bridge machines
-
No “killer application to optimize for, large chunks of compute are data locality bound and CPU stall bound, suggests that 2 wide SMT is not sufficient to eliminate the bulk of the overheads
- What is a 2 wide SMT anyways?
- I’m assuming it means 2 instructions at once, but not all instructions are parallelizable
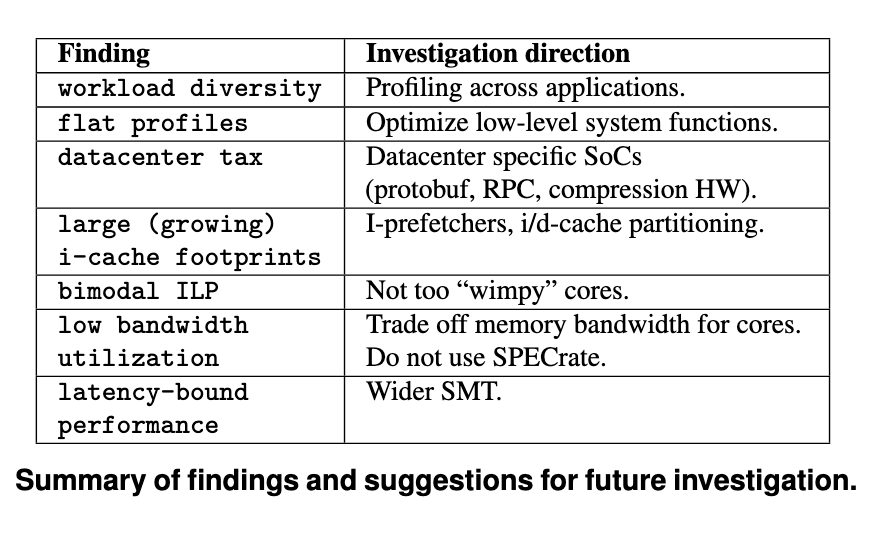
- workload diversity is very real, we’ve gotten a range of compute that’s wide enough for this not to matter
- At the start, 50 hottest binaries account for 80% of execution
- Three years later, top 50 are only 60%
- Coverage decreases more than 5% per over the course of 3 years
- Also does not include public clouds
- Applications, as they grow more diverse and fatter, have gotten more flat profiles themselves
- What would this look like for chatd?
-
“Data center tax” is very real, large chunks of your machine are going to be devoted to doing logging, rpc, ser/des
-
Yacine: top down measurement? never heard of this before
- Yasin, Ahmad. “A Top-Down Method for Performance Analysis and Counters Architecture.” In 2014 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 35–44, 2014. https://doi.org/10.1109/ISPASS.2014.6844459.
- Talks about core front-end and core back-end, what is that?
- Front end:
- instruction fetch
- decode unit
- branch prediction
- uop cache
- loop stream detector (?) - optimizes tight loops
- Back end:
- sched/reservation station
- execution units
- reorder buffer
- register file
- load/store units
- Front end:
- Top down classifies pipeline slots into retiring (useful work), frontend bounc, backend bound, and bad speculation
- They believe that cache problems (lots of lukewarm code) is why the frontend is the primary staller
- i.e. binaries with 100s of mb
-
memcpyandmemove()is 4-5% of datacenter cycles- as is encryption
-
25% of datacenter tax is compressing and decompressing data
Dhalion
- This paper was actually quite dull
- Interesting bit is the split: metrics -> symptoms -> many to many -> diagnoses -> many to many -> resolvers
- This whole thing is called a “policy”
- Control loop system, explodes in complexity
- Part of the control loop is blacklisting certain actions from occuring that previously didn’t move you towards your desired solution
PGO - Block 1 2026
Li, David Xinliang, Raksit Ashok, and Robert Hundt. “Lightweight Feedback-Directed Cross-Module Optimization.” Proceedings of the 8th Annual IEEE/ACM International Symposium on Code Generation and Optimization, ACM, April 24, 2010, 53–61. https://doi.org/10.1145/1772954.1772964.
- Two most important IPO passes are function inlining and indirect function call promotion
- Basically:
- We want to have a smarter way of combining things without making fat .o files
- We can use FDO analysis to determine which functions are hot and worth inlining or promoting
- In order to do so, we can use a greedy algorithm to generate families, which help link these together
- We push linking earlier by using the profiled data
- Profile data is augmented FDO data, so
- After training run is done, the in-memory info contains a callgraph, using a greedy clustering algorithm to decide on “friends”
- afterwards, we have a standard FDO data (raw counts of how many times each branch was taken), and also module grouping decisions
- In order to make this workable for Buck / Blaze / Bazel, an auxillery file needs to get shipped so the build system knows which sources to include, even when they’re not strictly dependant, as a form of dynamic dependency injection
- Predacessor to LTO (and ThinLTO)
- https://lists.llvm.org/pipermail/llvm-dev/2019-September/135393.html
Discussion
- Coming from FDO baseline is a bit specious
- What is a translation unit here?
Panchenko, Maksim, Rafael Auler, Bill Nell, and Guilherme Ottoni. “BOLT: A Practical Binary Optimizer for Data Centers and Beyond.” arXiv:1807.06735. Preprint, arXiv, October 12, 2018. https://doi.org/10.48550/arXiv.1807.06735.
- How does this interact with ASLR?
- I-cache much more constrained than Dcache
Chen, Dehao, David Xinliang Li, and Tipp Moseley. “AutoFDO: Automatic Feedback-Directed Optimization for Warehouse-Scale Applications.” Proceedings of the 2016 International Symposium on Code Generation and Optimization, February 29, 2016, 12–23. https://doi.org/10.1145/2854038.2854044.
- Largely leverages the LBT, but also has to decide on the CFG
- The control flow graph has some nuances
- Optimization is one way, a binary once optimized may not be easily reversible back. Inlined functions are destructive transforms
- Context sensitive -> it uses the path taken to measure hotness for a function
- i.e. foo -> bar -> baz. Baz might be cold globally, but baz might be really hot for the path itself
- Calculating edge frequency
- Moves data into equvilance classes
- Basic blocks within the same loop or dominated by the same condition have the same equivlance class
- A function might be frequently called, but the functions inside it are varied, so we need the calling context
- Flow based heuristic is iterative
- Moves data into equvilance classes
- Compiler needs to basically map the control flow structure to map what’s show in the profiler
Ayers, Grant, Nayana Prasad Nagendra, David I. August, et al. “AsmDB: Understanding and Mitigating Front-End Stalls in Warehouse-Scale Computers.” Proceedings of the 46th International Symposium on Computer Architecture, June 22, 2019, 462–73. https://doi.org/10.1145/3307650.3322234.
- icache is frontend, and must be saved, because there’s no out of order execuation
- figure 12 - multiple basic blocks are blocked
- Think hard about basic blocks and how they relate to this
Jamilan, Saba, Tanvir Ahmed Khan, Grant Ayers, Baris Kasikci, and Heiner Litz. “APT-GET: Profile-Guided Timely Software Prefetching.” Proceedings of the Seventeenth European Conference on Computer Systems, March 28, 2022, 747–64. https://doi.org/10.1145/3492321.3519583.
- Uses the cycle counter in the LBR
- Uses the graph only, out of the CRONO suite
Shen, Han, Krzysztof Pszeniczny, Rahman Lavaee, Snehasish Kumar, Sriraman Tallam, and Xinliang David Li. “Propeller: A Profile Guided, Relinking Optimizer for Warehouse-Scale Applications.” Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, January 27, 2023, 617–31. https://doi.org/10.1145/3575693.3575727.
Disassembly is one of the primary serializing bottlenecks in state of the art PLO tools [52]. Accurate recursive disassembly [7] of complex applications is challenging to distribute across many machines due to the incremental nature of discovery.
Why? Can we not parallelize these?
Rec Sys (March 2026)
Covington, Paul, Jay Adams, and Emre Sargin. “Deep Neural Networks for YouTube Recommendations.” Proceedings of the 10th ACM Conference on Recommender Systems, September 7, 2016, 191–98. https://doi.org/10.1145/2959100.2959190.
- uses negative samples